Predictive Maintenance – a short introduction

The main objectives of Predictive Maintenance, i.e. the prediction of necessary maintenance work or general downtime, are
- the efficient use of resources by maximising availability,
- the saving of operating costs, by preventing unnecessary downtime or poor quality rejects.
If, for example, the use of predictive models enables the failure of certain parts of the production chain to be predicted with a high degree of probability before it occurs, this failure can be prevented and the costs caused by defective production pieces can be reduced.
Concrete modelling objectives of predictive maintenance are therefore e.g. given by:
- The early detection and/or prediction of anomalies in characteristics of the production piece or in time series of sensor data.
- The estimation of remaining lifetimes of resources.
- The prediction of probabilities for faulty behaviour in the following time window.
- Identifying cause-and-effect relationships that lead to failure.
To pursue these goals, not only statistical methods but also machine learning methods are increasingly used [2]. As part of the Internet of Things more and more data about manufacturing machines is available, data-hungry methods such as deep neural networks are becoming more and more common [3]. Neural networks [4] have also pushed the limits of possibilities in the area of unstructured data in recent years, such as images. Today, images of workpieces can be automatically checked for abnormalities using these networks. Other famous methods and models in the area of classification and regression are, for example, decision trees, random forests, support vector machines [5], or even boosted variants of these models, for example AdaBoost or Gradient Boost [6]. Depending on the quality and quantity as well as the structure of the available data, it must be decided on a case-by-case basis which procedures deliver the best results.
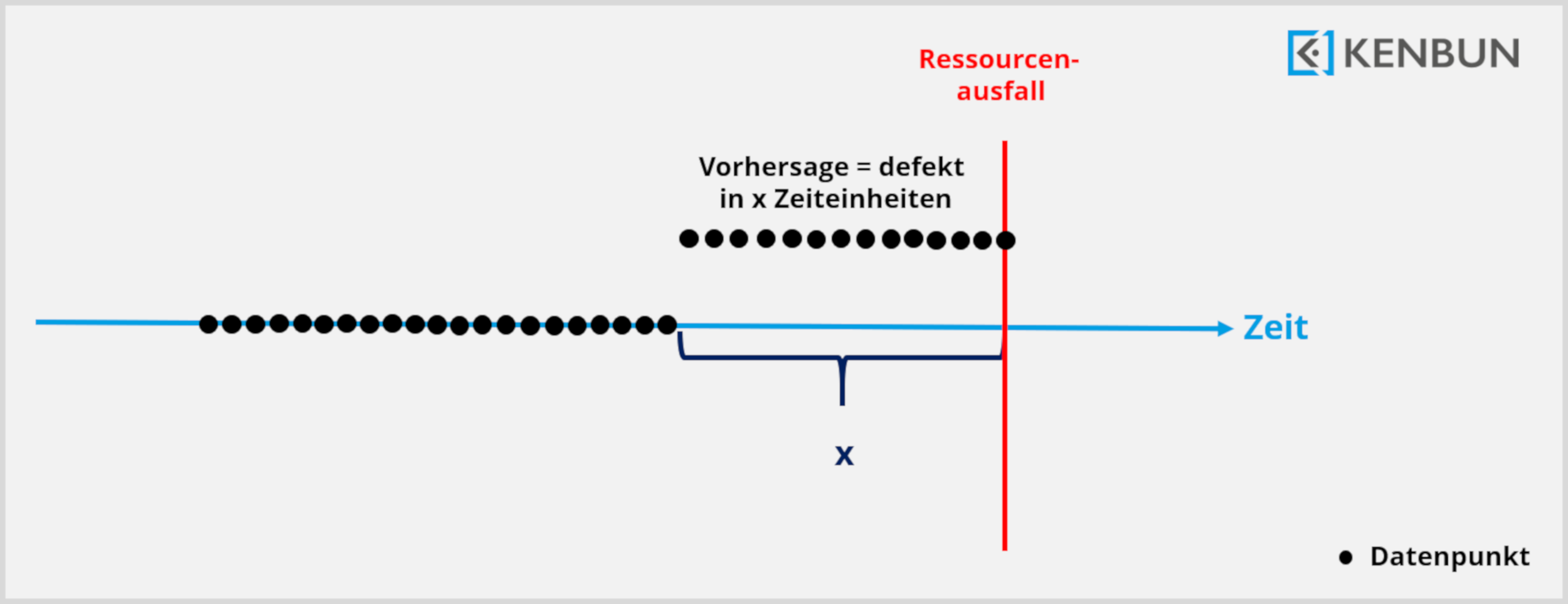
Abstract description of the input data and predictions of the model, e.g. the error probability in the next hour
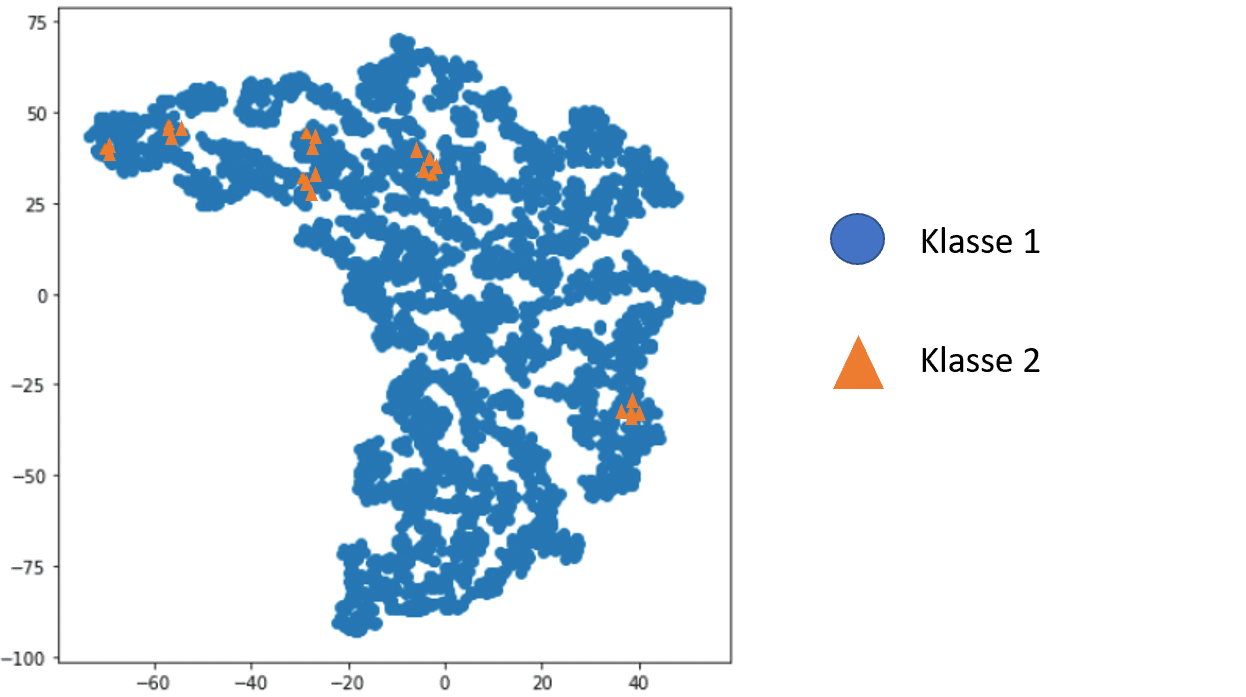
Illustration of two classes with very different class sizes.
The methods of predictive maintenance are applied e.g. in industry for the evaluation of big data generated by sensors connected in the Internet-of-Things [9], for milling machines, heat exchangers and robots [10] and many more [11].
If you also want to use the existing data of your company to allocate your resources efficiently and thus reduce your operating costs, please contact us. Let the experts at Kenbun IT AG support you and use the potential of Predictive Maintenance in your company.
[1] Mobley, R. Keith. An introduction to predictive maintenance (2nd ed.). Butterworth-Heinemann.
[3] Huuhtanen, T., et al., Predictive Maintenance of Photovoltaic Panels via Deep Learning, 01.08.2019.
[4] Goodfellow, I., et al., Deep Learning (2016).
[5] Hastie, T., et al., The Elements of Statistical Learning (2009).
[7] Aggarwal, C., Outlier Analysis (2017).
[8] Lema, G., et al, Imbalanced–learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning, Journal of Machine learning Research (2017), Volume 18, Nummer 17, S. 1-5.
[9] Gemü, Oracle IoT Cloud Service Helps Gemü Drive Safety and Quality, 01.08.2019.
[10] Bosch, Köhler, M, Industry 4.0: Predictive maintenance use cases in detail, 01.08.2019.
[11] Oracle, Trotman, W., 5 Use Cases for Predictive Maintenance and Big Data, 01.2019.